L'esperança matemàtica (o senzillament esperança) o mitjana d'una variable aleatòria és, en teoria de la probabilitat, la mitjana dels valors que pot prendre la variable ponderats per la probabilitat d'aquests valors. Representa el valor mitjà que un "espera" de la variable després d'un nombre elevat de repeticions de l'experiment aleatori. Val a dir que el valor que pren l'esperança matemàtica en alguns casos pot no ser "esperat" en el sentit més general de la paraula - el valor de l'esperança pot no ser un dels valors possibles de la variable; per exemple, el valor esperat quan llencem un dau equilibrat de 6 cares és 3,5 però 3,5 no és un valor possible al rodar el dau. Una aplicació comú de l'esperança matemàtica és en les apostes o els jocs d'atzar.
Història
Al segle xvii Blaise Pascal va estudiar un famós problema entre dos jugadors a petició d'Antoine Gombaud. El problema era que els dos jugadors que volien acabar un joc en el que participaven i volien dividir els diners que han apostat fins aquell moment de forma justa, basant-se en la probabilitat que cadascú té de guanyar el joc des d'aquell moment. Com han de trobar aquesta "quantitat justa"? El 1654 va mantenir correspondència amb Pierre de Fermat sobre el tema dels jocs d'atzar, i és en el debat sobre aquest problema que es van bastir els fonaments de la teoria matemàtica de les probabilitats i la noció de valor esperat.
L'ús de la lletra "E" per indicar el valor esperat es remunta a William Allen Whitworth (1901) "Choice and chance". El símbol s'ha tornat popular, ja que per als escriptors anglesos significa "Expectation", per als alemanys "Erwartungswert", i per als francesos "espérance".
Exemple introductori
Figura 1. Ruleta amb dos resultats possibles
Suposem que juguem amb una ruleta que només pot donar dos resultats: blanc amb probabilitat 3/5 i verd amb probabilitat 2/5, i apostem que quan surti blanc guanyarem 10 euros i quan surti verd en perdrem 2. Vegeu la Figura 1. Considerem una variable aleatòria que descriu aquesta situació:
Així, la variable aleatòria només pren els valors 10 i -2, però amb probabilitat més alta 10 que -2; i si volem resumir la variable en un únic nombre, haurem de tenir-ho en compte, ja que no és raonable dir que la mitjana dels valors que pren la variable és (10-2)/2=4. D'acord amb la interpretació freqüentista de les probabilitats, si participem vegades en aquest joc ( gran), aproximadament vegades guanyarem 10 euros i vegades perdrem 2 euros. La mitjana dels guanys entre totes les jugades serà, aproximadament,
Anomenarem esperança o mitjana de a
Càlcul de l'esperança de variable aleatòries
Variables aleatòries discretes que prenen un nombre finit de valors
Sigui una variable aleatòria discreta que pren els valors amb probabilitats respectivament. L'esperança de es calcula per
Exemples.
Si tenim un dau ordinari amb probabilitats
aleshores,
Mes generalment, si tenim una variable aleatòria uniforme sobre els punts , tots amb probabilitat , aleshores,
Si és una variable aleatòria amb distribució binomial de paràmetres i , és a dir, que pot prendre els valors 0,1,...,n, amb probabilitats:
aleshores
on al darrer sumatori hem fet el canvi , i després hem utilitzat que
on és una variable binomial de paràmetres i .
Variables aleatòries discretes que prenen un nombre infinit numerable de valors
Considerem ara una variable aleatòria que pot prendre un nombre infinit numerable de valors amb probabilitats respectivament. Aleshores la suma que apareix a (1) esdevé una sèrie infinita i cal anar amb cura. Concretament, l'esperança de [1] és
sempre que la sèrie anterior convergeixi absolutament, és a dir, Si es diu que no té esperança (o que no té esperança finita) o que l'esperança de no existeix.
Es tracta d'una distribució de Poisson de paràmetre 1 però que els valors de la variable alternen el signe. Comencem mirant si l'esperança de existeix:
on hem utilitzat el desenvolupament en serie de la funció exponencial: per a qualsevol Aleshores podem calcular l'esperança de :
2. Considerem ara una variable aleatòria discreta amb probabilitats
Aleshores
Per tant, l'esperança de no existeix.
Variables aleatòries absolutament contínues
Sigui una variable aleatòria amb funció de densitat . Aleshores l'esperança de es calcula per [2]
sempre que la integral anterior sigui absolutament convergent:
Exemples.
1. Variable normal estàndard. Sigui una variable aleatòria normal amb i , amb funció de densitat
Aleshores,
Llavors l'esperança de existeix i val:
2. Considerem una variable aleatòria amb distribució de Cauchy estàndard, amb funció de densitat
Aleshores
Per tant, l'esperança de no existeix.
Esperança d'una funció d'una variable aleatòria
Sigui una variable aleatòria. Ens ocuparem ara de calcular l'esperança d'una funció d'aquesta variable: (vegeu mes avall, a la definició general d'esperança matemàtica, les condicions sobre la funció ). Si és discreta, també ho serà i, d'acord amb les fórmules anteriors, per calcular hauríem de buscar primer la funció de probabilitat de ; la següent fórmula ens permet calcular l'esperança directament: amb les notacions anteriors,
sempre que . Si la variable pren només un nombre finit de valors, aleshores la suma és finita i sempre existeix l'esperança de .
Exemple. Considerem el cas del llançament del dau i la funció Aleshores
Anàlogament, en el cas absolutament continu, per calcular hauríem de buscar primer la densitat de , però ens ho podem estalviar gràcies a la següent fórmula:
sempre que
Exemple. Sigui una variable normal estàndard, i considerem com abans la funció Aleshores, integrant per parts,
Com que , la mateixa integral serveix per comprovar que l'esperança de existeix i per al càlcul d'aquesta esperança. A partir d'aquí, la variància de és
Jocs justos i esperança matemàtica
Si representa el benefici d'un jugador que aposta en un joc d'atzar, es diu que el joc és just si , és a dir, després d'estar jugant moltes partides, no ha guanyat ni perdut res: només ha passat l'estona. Tots els jocs d'atzar dels casinos, les loteries, etc, són jocs injustos (ningú posa un casino per filantropia): un jugador pot tenir sort en algunes jugades i guanyar, però si insisteix i va jugant, a la llarga, com que s'aplica la llei dels grans nombres i el teorema central del límit, el jugador acaba perdent.
Per exemple, la ruleta americana té 38 caselles equiprobables, numerades de l'1 al 36, una casella amb el 0 i una altra amb el doble 0. Si la bola va a parar a les caselles del 0 o del doble 0, el jugador perd tota l'aposta. El guany per encertar una aposta a un sol número (de l'1 al 36) paga de 35 a 1 (és a dir, cobrem 35 vegades el que hem apostat i recuperem l'aposta, de manera que rebem 36 vegades el que hem apostat). Per tant, considerant els 38 possibles resultats, l'esperança matemàtica del benefici per apostar a un sol número és:
Per tant un espera, en mitjana, perdre uns 5 cèntims per cada euro que aposta; d'una altra manera, el valor esperat per apostar 1 euro són 0,9474 euros.
Esperança i independència
Si i són dues variables aleatòries independents (ambdues amb esperança), aleshores,[3]
Llavors, la variància de la suma o la resta de i es simplifica:[4]
Mes generalment, si són variables aleatòries independents (totes amb esperança), aleshores [5]
La fórmula de la variància de la suma de les variables també es simplifica:
Esperança condicionada
Esperança condicionada per variables aleatòries discretes
Comencem estudiant un exemple:
Exemple. Traiem una paraula a l'atzar de la frase:
ÉS MASSA BO PER SER CERT
Considerem les següents variables aleatòries:
és el nombre de lletres que té la paraula que traiem.
és el nombre de vegades que la paraula té la lletra E .
La funció de probabilitat del vector ve donada a la taula següent (recordeu que l'expressió treure a l'atzar vol dir que s'utilitza una probabilitat uniforme, en aquest cas, que totes les paraules tenen probabilitat 1/6):
A partir d'aquesta taula, sumant per files o columnes, o be directament calculant les probabilitats, es dedueixen les funcions de probabilitat de les variables i :
Les probabilitats condicionades es calculen per la fórmula
Llavors tenim les següents taules:
Ara podem calcular l'esperança de condicionada per , on cal distingir dos casos, segons els valors de :
Aquesta és la mitjana de les paraules que no tenen cap E.
Anàlogament és calcula que és la mitjana de les paraules que tenen una E. Aquestes dues expressions les podem resumir en
Veiem així que és una nova variable aleatòria que és funció de la variable .
Cas discret general
Donades dues variables aleatòries discretes, que pot prendre els valors i que té esperança, i que pot prendre els valors (suposem que ) definim l'esperança de condicionada[6]per
on és la probabilitat de l'esdeveniment condicionada a :
Podem resumir tots els casos de les esperances condicionades als diferents en una nova variable aleatòria designada per i anomenada esperança de condicionada per :
Tenim que
on hem utilitzat que del fet que té esperança es dedueix que la sèrie doble que apareix és absolutament convergent i, per tant, es poden commutar els sumatoris,[7] i que
La part dreta de l'equació s'anomena esperança iterada.
Comentari. L'esperança condicionada ens dona el valor de l'esperança de segons els valors de . En Estadística, l'esperança condicionada correspon a la idea de calcular la mitjana d'una població per estrats; per exemple, si estem analitzant les alçades d'una població que tenim dividida en homes i dones (els estrats), podem calcular la mitjana per als homes i per a les dones. Si calculem la mitjana de les mitjanes, ponderades segons la importància dels estrats, obtindrem la mitjana de tota la població, que és el que diu la fórmula de l'esperança total.
Esperança condicionada per a variables absolutament contínues
Sigui un vector aleatori absolutament continu, amb funció de densitat conjunta , i amb funció de densitat (densitat marginal). Per a tal que es defineix la funció de densitat de condicionada per
Quan és tal que , aleshores es pot prendre com a qualsevol funció de densitat, ja que no té transcendència en cap càlcul; a la pràctica, normalment no es concreta aquesta densitat.
Si suposem que la variable té esperança, aleshores l'esperança de condicionada per és [6]
Com que hem integrat respecte , l'expressió queda una funció de : posem
i, tal com fèiem en el cas discret, podem definir una nova variable aleatòria
La variable s'anomena esperança de condicionada per .
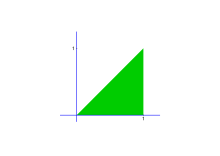
Figura 2. La funció de densitat conjunta val 2 sobre el triangle T i zero fora.
Exemple. Sigui un vector aleatori bidimensional amb distribució uniforme en el triangle de vèrtexs els punts (0,0), (1,0) i (1,1). La funció de densitat conjunta (vegeu la Figura 2) és
La funció de densitat de es calcula per la fórmula:
Ara cal distingir dos casos:
1. Fixada , aleshores . És evident que
2. Fixada ,
Llavors
Ajuntant ambdós casos tenim
Ara ja podem calcular la densitat condicionada . Tal com hem comentat, només la calcularem per a
Figura 3. Funció de densitat condicionada
Vegeu la Figura 3. Noteu que els papers de i de són completament diferents. Fixada la tenim una funció de densitat en . De fet, en aquest cas, es tracta de la densitat d'una distribució uniforme en l'interval
Ara ja podem calcular l'esperança condicionada de condicionada per , que només es calcula per , que són els valors de que poden sortir:
Tal com comentàvem, aquesta és una funció de : Llavors,
Formula de l'esperança total en el cas absolutament continu.[6]
Definició general d'esperança
En general, si és una variable aleatòria definida en un espai de probabilitat i integrable respecte a la mesura de probabilitat P, aleshores l'esperança matemàtica de (denotada o de vegades o ) es defineix com a[8]
on la integral és una integral de Lebesgue respecte a la mesura de probabilitat P. La condició que l'esperança de existeixi és que .
Designem per la llei o distribució de la variable aleatòria , és a dir, la probabilitat, sobre l'espai mesurable , on és la -àlgebra de Borel sobre el conjunt dels nombre reals, definida de la següent manera: per qualsevol ,
on, a la darrera integral és una integral de Lebesgue-Stieltjes [10] respecte la funció de distribució de :
Les fórmules que hem vist a la secció del càlcul de l'esperança s'obtenen d'aplicar la igualtat (2) als casos discret i absolutament continus.
Si és una funció mesurable respecte la -àlgebra de Borel, tal que té esperança, és a dir, , aleshores
d'on surten les fórmules del cas discret i absolutament continu que hem vist més amunt.
Observacions:
La funció no cal que estigui definida a tot , sinó només al conjunt on pren valors la variable . Per exemple, si és discreta, ha d'estar definida en el conjunt dels punts tals que . O si és una variable no negativa, aleshores n'hi ha prou que estigui definida a .






























































































































![{\displaystyle E(X)=\int _{-\infty }^{\infty }E[X|Y=y]\,f_{Y}(y)\,dy.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b289e3ca57cbf8074851c90b8936752e9f56e4e2)














![{\displaystyle F(x)=P(X\leq x)=P_{X}{\big (}(-\infty ,x]{\big )}.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b492eaadd0a435ab8bd5c3fb6c03a3c81eee790b)




















