En Teoría de Probabilidad y Estadística, la distribución exponencial es una distribución continua que se utiliza para modelar tiempos de espera para la ocurrencia de un cierto evento. Esta distribución al igual que la distribución geométrica tiene la propiedad de pérdida de memoria. La distribución exponencial es un caso particular de la distribución gamma.
Definición
Función de Densidad
Se dice que una variable aleatoria continua tiene una distribución exponencial con parámetro y escribimos si su función de densidad es
La distribución exponencial en ocasiones se parametriza en términos del parámetro de escala en cuya caso, la función de densidad será
para .
Función de Supervivencia
De forma adicional esta distribución presenta una función adicional que es función Supervivencia (S), que representa el complemento de la Función de distribución.
El valor condicional en riesgo (CVaR) también conocido como déficit esperado o supercuantil para Exp(λ) se obtiene de la siguiente manera:[1]
Probabilidad de superación amortiguada (bPOE)
La probabilidad amortiguada de superación es uno menos el nivel de probabilidad en el que el CVaR es igual al umbral . Se obtiene de la siguiente manera:[1]
Divergencia de Kullback-Leibler
La divergencia de Kullback-Leibler dirigida en nats de (distribution de aproximación) de (distribución "verdadera") viene dada por
Distribución de máxima entropía
Entre todas las distribuciones de probabilidad continuas con soporte cerrada-abierta 0, ∞ y media μ, la distribución exponencial con λ = 1/μ tiene la mayor entropía diferencial. En otras palabras, es la distribución de probabilidad de máxima entropía para una variante aleatoria X que es mayor o igual que cero y para la que E[X] es fija.[2]
Distribución del mínimo de variables aleatorias exponenciales
Sean X1, ..., Xn variables aleatorias exponencialmente distribuidas con parámetros de tasa λ1, ..., λn. Entonces
también se distribuye exponencialmente, con el parámetro
Esto puede verse considerando la función de distribución acumulativa complementaria:
El índice de la variable que alcanza el mínimo se distribuye según la distribución categórica
Puede verse una prueba dejando que . Entonces,
Nótese que
no es una distribución exponencial, si X1, …, Xn no todos tienen parámetro 0.[3]
Momentos conjuntos de estadísticos de orden exponencial i.i.d
Esto puede verse invocando la ley de la expectativa total y la propiedad sin memoria:
La primera ecuación se sigue de la ley de la expectativa total. La segunda ecuación explota el hecho de que una vez que condicionamos en , debe seguirse que . La tercera ecuación se basa en la propiedad sin memoria para reemplazar con .
Ejemplo
Ejemplos para la distribución exponencial es la distribución de la longitud de los intervalos de una variable continua que transcurren entre dos sucesos, que se distribuyen según la distribución de Poisson.
El tiempo transcurrido en un centro de llamadas hasta recibir la primera llamada del día se podría modelar como una exponencial.
El intervalo de tiempo entre terremotos (de una determinada magnitud) sigue una distribución exponencial.
Supongamos una máquina que produce hilo de alambre, la cantidad de metros de alambre hasta encontrar una falla en el alambre se podría modelar como una exponencial.
En fiabilidad de sistemas, un dispositivo con tasa de fallo constante sigue una distribución exponencial.
Distribuciones Relacionadas
Si entonces .
Si entonces .
Si entonces .
Si son variables aleatorias independientes tales que entonces , donde es la distribución de Erlang con parámetros y , esto es . Es decir, la suma de variables aleatorias independientes con distribución exponencial con parámetro es una variable aleatoria con distribución de Erlang.
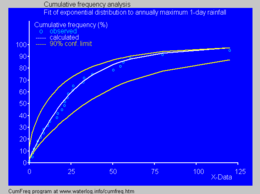
Distribución cumulativa ajustada a máximos anuales de lluvias diarias[4]
Inferencia Estadística
Suponga que es una variable aleatoria tal que y es una muestra proveniente de .
En la hidrología, la distribución exponencial se emplea para analizar variables aleatorias extremos de variables como máximos mensuales y anuales de la precipitación diaria.[5]
La imagen azul ilustra un ejemplo de ajuste de la distribución exponencial a lluvias máximas diárias anuales ordenadas, mostrando también la franja de 90% de confianza, basada en la distribución binomial. Las observaciones presentan los marcadores de posición, como parte del análisis de frecuencia acumulada.
↑ abNorton, Matthew; Khokhlov, Valentyn; Uryasev, Stan (2019). «Calculating CVaR and bPOE for common probability distributions with application to portfolio optimization and density estimation». Annals of Operations Research (Springer) 299 (1- 2): 1281-1315. doi:10.1007/s10479-019-03373-1. Archivado desde el original el 31 de marzo de 2023. Consultado el 27 de febrero de 2023.
↑Park, Sung Y.; Bera, Anil K. (2009). «Modelo de heteroscedasticidad condicional autorregresiva de entropía máxima». Journal of Econometrics (Elsevier) 150 (2): 219-230. Archivado desde el original el 7 de marzo de 2016. Consultado el 2 de junio de 2011.
↑Michael, Lugo. «The expectation of the maximum of exponentials». Archivado desde el original el 20 de diciembre de 2016. Consultado el 13 de diciembre de 2016.
↑Cumfreq, a free computer program for cumulative frequency analysis and probability distribution fitting. [1]
↑Ritzema (ed.), H.P. (1994). Frequency and Regression Analysis. Chapter 6 in: Drainage Principles and Applications, Publication 16, International Institute for Land Reclamation and Improvement (ILRI), Wageningen, The Netherlands. pp. 175-224. ISBN 90-70754-33-9.
Enlaces externos
Calculadora Distribución exponencial
[http://cajael.com/mestadisticos/T7DContinuas/node20.php(enlace roto disponible en Internet Archive; véase el historial, la primera versión y la última).] Calcular la probabilidad de una distribución exponencial con R (lenguaje de programación)























![{\displaystyle S(x)=\operatorname {P} [X>x]=\left\{{\begin{matrix}1&{\text{para }}x<0\\e^{-\lambda x}&{\text{para }}x\geq 0\end{matrix}}\right.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f303c8ef0dd1109d464e3efd1ce1abd00067ade2)
![{\displaystyle \operatorname {E} [X]={\frac {1}{\lambda }}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b73f390ebc9ba94630076990a6d8cdb39c7b2e3c)
![{\displaystyle \operatorname {Var} [X]={\frac {1}{\lambda ^{2}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a568b295dd8fd94661a9ebbb0f4ef4c7df8625e3)

![{\displaystyle \operatorname {E} [X^{n}]={\frac {n!}{\lambda ^{n}}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7e9cdded24c663acdfe60cb3188eedda2d402680)





![{\displaystyle \operatorname {P} [X>x+y|X>y]=\operatorname {P} [X>x]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8fc3596bcdd6f77e68d8aa947d20b498bc8fac6b)
![{\displaystyle {\begin{aligned}\operatorname {P} [X>x+y|X>y]&={\frac {\operatorname {P} [X>x+y\cap X>y]}{\operatorname {P} [X>y]}}\\&={\frac {\operatorname {P} [X>x+y]}{\operatorname {P} [X>y]}}\\&={\frac {e^{-\lambda (x+y)}}{e^{-\lambda y}}}\\&=e^{-\lambda x}\\&=\operatorname {P} [X>x]\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/a25c363af2bbaa0f3668733f6c6e3012d3552082)




![{\displaystyle {\begin{aligned}{\bar {q}}_{\alpha }(X)&={\frac {1}{1-\alpha }}\int _{\alpha }^{1}q_{p}(X)dp\\&={\frac {1}{(1-\alpha )}}\int _{\alpha }^{1}{\frac {-\ln(1-p)}{\lambda }}dp\\&={\frac {-1}{\lambda (1-\alpha )}}\int _{1-\alpha }^{0}-\ln(y)dy\\&={\frac {-1}{\lambda (1-\alpha )}}\int _{0}^{1-\alpha }\ln(y)dy\\&={\frac {-1}{\lambda (1-\alpha )}}[(1-\alpha )\ln(1-\alpha )-(1-\alpha )]\\&={\frac {-\ln(1-\alpha )+1}{\lambda }}\\\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/8cb6c9508565c42978ca1153dc0f6bfd0199a45c)















![{\displaystyle \operatorname {E} \left[X_{(i)}X_{(j)}\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/7d350557a602c2566c092558fff0aefb0049c7c9)


![{\displaystyle {\begin{aligned}\operatorname {E} \left[X_{(i)}X_{(j)}\right]&=\sum _{k=0}^{j-1}{\frac {1}{(n-k)\lambda }}\operatorname {E} \left[X_{(i)}\right]+\operatorname {E} \left[X_{(i)}^{2}\right]\\&=\sum _{k=0}^{j-1}{\frac {1}{(n-k)\lambda }}\sum _{k=0}^{i-1}{\frac {1}{(n-k)\lambda }}+\sum _{k=0}^{i-1}{\frac {1}{((n-k)\lambda )^{2}}}+\left(\sum _{k=0}^{i-1}{\frac {1}{(n-k)\lambda }}\right)^{2}.\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/0135f144a56c4b7565f7faa61cc3abb42afe9c0d)
![{\displaystyle {\begin{aligned}\operatorname {E} \left[X_{(i)}X_{(j)}\right]&=\int _{0}^{\infty }\operatorname {E} \left[X_{(i)}X_{(j)}\mid X_{(i)}=x\right]f_{X_{(i)}}(x)\,dx\\&=\int _{x=0}^{\infty }x\operatorname {E} \left[X_{(j)}\mid X_{(j)}\geq x\right]f_{X_{(i)}}(x)\,dx&&\left({\textrm {since}}~X_{(i)}=x\implies X_{(j)}\geq x\right)\\&=\int _{x=0}^{\infty }x\left[\operatorname {E} \left[X_{(j)}\right]+x\right]f_{X_{(i)}}(x)\,dx&&\left({\text{by the memoryless property}}\right)\\&=\sum _{k=0}^{j-1}{\frac {1}{(n-k)\lambda }}\operatorname {E} \left[X_{(i)}\right]+\operatorname {E} \left[X_{(i)}^{2}\right].\end{aligned}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/be5949313f3639a86ac81484ac8ca7f4f9edb4d4)


![{\displaystyle operatornameE\left[X_{(j)}\mid X_{(j)}\geq x\right]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b969e74e16101839ce0a957f4842acb49f16b7b2)
![{\displaystyle \operatorname {E} \left[X_{(j)}\right]+x}](https://wikimedia.org/api/rest_v1/media/math/render/svg/775aa6cfd6c5d2b1e4b70ce3108a17f93f7b0224)




















![{\displaystyle \operatorname {E} [{\hat {\lambda }}]\neq \lambda }](https://wikimedia.org/api/rest_v1/media/math/render/svg/74ee1ea5ee71387651481abe1999049cb49bb39a)




 Datos: Q237193
Datos: Q237193 Multimedia: Exponential distribution / Q237193
Multimedia: Exponential distribution / Q237193









