GPT-2
| GPT-2 | ||
|---|---|---|
 | ||
| Información general | ||
| Tipo de programa | LLM | |
| Lanzamiento inicial | 14 de febrero de 2019 | |
| Lanzamientos | ||
| GPT-1 | GPT-2 | GPT-3 |
| Enlaces | ||
| Sitio web oficial Repositorio de código | ||
[editar datos en Wikidata] | ||
Generative Pre-trained Transformer 2 (GPT-2) es un gran modelo de lenguaje desarrollado por OpenAI y el segundo en su serie fundamental de modelos GPT. GPT-2 fue pre-entrenado en un conjunto de datos de 8 millones de páginas web.[1] Fue lanzado parcialmente en febrero de 2019, seguido por el lanzamiento completo del modelo de 1.5 mil millones de parámetros el 5 de noviembre de 2019.[2][3][4][5][6]
GPT-2 fue creado como una "escala directa" de GPT-1[7] con un aumento de diez veces tanto en el número de sus parámetros como en el tamaño de su conjunto de datos de entrenamiento.[8] Es un aprendiz general y su capacidad para realizar varias tareas fue una consecuencia de su habilidad general para predecir con precisión el siguiente ítem en una secuencia,[9][10] lo que le permitió traducir textos, responder preguntas sobre un tema a partir de un texto, resumir pasajes de un texto más extenso,[10] y generar texto a un nivel a veces indistinguible del humano,[11] sin embargo, podía volverse repetitivo o sin sentido al generar pasajes largos.[12] Fue superado por los modelos GPT-3 y GPT-4, que ya no son de código abierto.
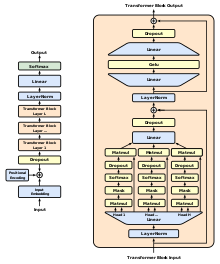
GPT-2, al igual que su predecesor GPT-1 y sus sucesores GPT-3 y GPT-4, tiene una arquitectura de transformador pre-entrenado generativo, implementando una red neuronal profunda, específicamente un modelo de transformador, que utiliza atención en lugar de arquitecturas anteriores basadas en recurrencia y convolución.[13] Los mecanismos de atención permiten que el modelo se enfoque selectivamente en segmentos del texto de entrada que predice que son los más relevantes.[14][15] Este modelo permite una gran paralelización, y supera los benchmarks anteriores para modelos basados en RNN/CNN/LSTM.[16][17]
Limitaciones
GPT-2 está diseñado para generar texto natural, completamente coherente y casi indistinguible de aquel realizado por humanos. Aun así se han detectado una serie de errores que presenta este sistema.
Si la extensión de un texto es corta, previsiblemente no se podrá encontrar ningún error, pero cuando esta pasa de una página, el sistema puede empezar a fallar y a mostrar más errores cuanto más largo sea el texto.[18] El sistema puede empezar a presentar repeticiones excesivas del texto, cambios de tema antinaturales y errores factuales, así como describir un incendio dentro del mar, por ejemplo.[19]
Por otro lado, el sistema está más familiarizado con los temas más habituales o usuales en la red así como el Brexit o Miley Cyrus, por lo que es más probable que genere textos realistas sobre estos temas que sobre temas más técnicos como la mecánica cuántica, por ejemplo.
En cuanto a la respuesta de preguntas, The Register, una web sobre notícias tecnológicas, después de analizar minuciosamente el sistema, reconoció que hay otros sistemas con otros tipos de algoritmos que desarrollan mejor esta tarea.[20]
Polémica
Este sistema puede ser utilizado, entre otras cosas, para crear fake news. Un ejemplo de ello es una notícia sobre el descubrimiento de unicornios. El sistema GPT-2 completó la noticia (que había sido generada manualmente) con información fictícia, creando así una notícia que podía pasar por real:
"Dr. Jorge Pérez, an evolutionary biologist from the University of La Paz, and several companions, were exploring the Andes Mountains when they found a small valley, with no other animals or humans. Pérez noticed that the valley had what appeared to be a natural fountain, surrounded by two peaks of rock and silver snow.
Pérez and the others then ventured further into the valley. “By the time we reached the top of one peak, the water looked blue, with some crystals on top,” said Pérez.
Pérez and his friends were astonished to see the unicorn herd. These creatures could be seen from the air without having to move too much to see them – they were so close they could touch their horns."
Fragmento de la noticia del descubrimiento de unicornios generada por GPT-2[21]
Una demostración de cómo de poderosa es esta herramienta es The book of Veles. Jonas Bendiksen, un fotógrafo noruego, publicó un libro con textos y frases falsas generadas con este sistema. Lo alimentó con artículos en inglés sobre la indústria de las noticias falsas de Veles. De esta manera, GPT-2 realizó un gran ensayo de 5.000 palabras y con múltiples citas de manera completamente autónoma, aunque están basadas en frases de personas reales. De esta misma forma, Bendiksen introdujo al sistema todo el Libro de Veles, un libro religioso de los pueblos eslavos para así obtener frases “antiguas” para introducir al libro.[22]
Referencias
- ↑ Radford, Alec; Wu, Jeffrey; Child, Rewon; Luan, David; Amodei, Dario; Sutskever, Ilua (14 de febrero de 2019). «Language models are unsupervised multitask learners». OpenAI 1 (8). Archivado desde el original el 6 de febrero de 2021. Consultado el 19 de diciembre de 2020.
- ↑ Vincent, James (7 de noviembre de 2019). «OpenAI has published the text-generating AI it said was too dangerous to share». The Verge. Archivado desde el original el 11 de junio de 2020. Consultado el 19 de diciembre de 2020.
- ↑ «GPT-2: 1.5B Release». OpenAI (en inglés). 5 de noviembre de 2019. Archivado desde el original el 14 de noviembre de 2019. Consultado el 14 de noviembre de 2019.
- ↑ Piper, Kelsey (15 de mayo de 2019). «A poetry-writing AI has just been unveiled. It's ... pretty good.». Vox. Archivado desde el original el 7 de noviembre de 2020. Consultado el 19 de diciembre de 2020.
- ↑ Johnson, Khari (20 de agosto de 2019). «OpenAI releases curtailed version of GPT-2 language model». VentureBeat. Archivado desde el original el 18 de diciembre de 2020. Consultado el 19 de diciembre de 2020.
- ↑ «Better Language Models and Their Implications». OpenAI. 14 de febrero de 2019. Archivado desde el original el 19 de diciembre de 2020. Consultado el 19 de diciembre de 2020.
- ↑ Radford, Alec; Narasimhan, Karthik; Salimans, Tim; Sutskever, Ilya (11 de junio de 2018). «Improving Language Understanding by Generative Pre-Training». OpenAI. p. 12. Archivado desde el original el 26 de enero de 2021. Consultado el 23 de enero de 2021.
- ↑ «Better Language Models and Their Implications». OpenAI. 14 de febrero de 2019. Archivado desde el original el 19 de diciembre de 2020. Consultado el 19 de diciembre de 2020.
- ↑ Radford, Alec; Wu, Jeffrey; Child, Rewon; Luan, David; Amodei, Dario; Sutskever, Ilua (14 de febrero de 2019). «Language models are unsupervised multitask learners». OpenAI 1 (8). Archivado desde el original el 6 de febrero de 2021. Consultado el 19 de diciembre de 2020.
- ↑ a b Hegde, Chaitra; Patil, Shrikumar (2020-06-09). «Unsupervised Paraphrase Generation using Pre-trained Language Models». arXiv:2006.05477 [cs.CL].
- ↑ Kaiser, Caleb (31 de enero de 2020). «Too big to deploy: How GPT-2 is breaking servers». Towards Data Science. Archivado desde el original el 15 de febrero de 2020. Consultado el 27 de febrero de 2021.
- ↑ Hern, Alex (14 de febrero de 2019). «New AI fake text generator may be too dangerous to release, say creators». The Guardian. Archivado desde el original el 14 de febrero de 2019. Consultado el 19 de diciembre de 2020.
- ↑ Radford, Alec; Narasimhan, Karthik; Salimans, Tim; Sutskever, Ilya (11 de junio de 2018). «Improving Language Understanding by Generative Pre-Training». OpenAI. p. 12. Archivado desde el original el 26 de enero de 2021. Consultado el 23 de enero de 2021.
- ↑ Bahdanau, Dzmitry; Cho, Kyunghyun; Bengio, Yoshua (2014-09-01). «Neural Machine Translation by Jointly Learning to Align and Translate». arXiv:1409.0473 [cs.CL].
- ↑ Luong, Minh-Thang; Pham, Hieu; Manning, Christopher D. (2015-08-17). «Effective Approaches to Attention-based Neural Machine Translation». arXiv:1508.04025 [cs.CL].
- ↑ Vaswani, Ashish; Shazeer, Noam; Parmar, Niki; Uszkoreit, Jakob; Jones, Llion; Gomez, Aidan N; Kaiser, Łukasz; Polosukhin, Illia (2017). «Attention is All you Need». Advances in Neural Information Processing Systems (Curran Associates, Inc.) 30.
- ↑ Olah, Chris; Carter, Shan (8 de septiembre de 2016). «Attention and Augmented Recurrent Neural Networks». Distill 1 (9). doi:10.23915/distill.00001. Archivado desde el original el 22 de diciembre de 2020. Consultado el 22 de enero de 2021.
- ↑ Piper, Kelsey (14 de febrero de 2019). «An AI helped us write this article». Vox (en inglés). Consultado el 16 de diciembre de 2021.
- ↑ «Better Language Models and Their Implications». OpenAI (en inglés). 14 de febrero de 2019. Consultado el 16 de diciembre de 2021.
- ↑ Quach, Katyanna. «Roses are red, this is sublime: We fed OpenAI's latest chat bot a classic Reg headline». www.theregister.com (en inglés). Consultado el 16 de diciembre de 2021.
- ↑ «OpenAI finally releases “dangerous” language model GPT-2». JAXenter (en inglés estadounidense). 7 de noviembre de 2019. Consultado el 16 de diciembre de 2021.
- ↑ reloj, Cartier Bresson no es un (29 de septiembre de 2021). «El gran engaño de 'The Book of Veles': el libro del fotógrafo de Magnum Jonas Bendiksen sacude el fotoperiodismo y la fotografía documental». Cartier-Bresson no es un reloj. Consultado el 16 de diciembre de 2021.
Enlaces externos
- https://www.openai.com/blog/gpt-2-1-5b-release/ Página web oficial
| Control de autoridades |
|
|---|
 Datos: Q95726727
Datos: Q95726727











