Resource Description Framework
Pour les articles homonymes, voir RDF.
RDF
Resource Description Framework
Resource Description Framework
Logo du cadre de description RDF
| Développé par | World Wide Web Consortium |
|---|---|
| Version initiale |  |
| Type de format | Graphe |
| Conteneur de fichiers | RDF Schema, Web Ontology Language |
| Origine de | RDF Schema |
| Norme | RDF 1.1 |
| Spécification | Format ouvert |
| Site web | RDF 1.1 Concepts and Abstract Syntax |
modifier - modifier le code - modifier Wikidata
Resource Description Framework (RDF) est un modèle de graphe destiné à décrire formellement les ressources Web et leurs métadonnées, afin de permettre le traitement automatique de telles descriptions. Développé par le W3C, RDF est le langage de base du Web sémantique. L'une des syntaxes (ou sérialisations) de ce langage est RDF/XML. D'autres syntaxes de RDF sont apparues ensuite, cherchant à rendre la lecture plus compréhensible ; c'est le cas par exemple de Notation3 (ou N3).
En annotant des documents non structurés et en servant d'interface pour des applications et des documents structurés, telles que les bases de données et la GED, RDF permet une certaine interopérabilité entre des applications échangeant de l'information non formalisée et non structurée sur le Web.
Principes fondamentaux
Un document structuré en RDF est un ensemble de triplets.
Un triplet RDF est une association (sujet, prédicat, objet) :
- le « sujet » représente la ressource à décrire ;
- le « prédicat » représente un type de propriété applicable à cette ressource ;
- l' « objet » représente une donnée ou une autre ressource : c'est la valeur de la propriété.
Le sujet et l'objet, dans le cas où ce sont des ressources, peuvent être identifiés par un URI ou être des nœuds anonymes. Le prédicat est nécessairement identifié par un URI.
Les documents RDF peuvent être écrits en différentes syntaxes, y compris en XML. Mais RDF en soi n'est pas un dialecte XML. Il est possible d'avoir recours à d'autres syntaxes pour exprimer les triplets. RDF est simplement une structure de données constituée de nœuds et organisée en graphe. Bien que RDF/XML — sa version XML proposée par le W3C — ne soit qu'une syntaxe (ou sérialisation) du modèle, elle est souvent appelée RDF, par abus de langage.
Un document RDF ainsi formé correspond à un multigraphe orienté étiqueté. Chaque triplet correspond alors à une arête orientée dont l'étiquette est le prédicat, le nœud source est le sujet et le nœud cible est l'objet.
La sémantique d'un document RDF peut être exprimée en théorie des ensembles et en théorie des modèles en se donnant des contraintes sur le monde qui peuvent être décrites en RDF. RDF hérite alors de la généricité et de l'universalité de la notion d'ensemble. Cette sémantique peut être aussi traduite en formule de logique du premier ordre, positive, conjonctive et existentielle :
- {sujet, objet, prédicat} ⇔ prédicat(objet, sujet)
ce qui est équivalent à :
- ∃ objet, ∃ sujet, prédicat(objet, sujet)
Le W3C a prévu un mécanisme d'inférence pour la sémantique de RDF déduisant exclusivement et intégralement les conséquences des prédicats, sans que ce mécanisme ne fasse l'objet d'une recommandation.
Vocabulaires RDF
La structure de RDF est extrêmement générique et sert de base à un certain nombre de schémas ou vocabulaires dédiés à des applications spécifiques. Une partie de ces vocabulaires est spécifiée par le W3C, comme les langages d'ontologie RDFS et OWL, ou le vocabulaire SKOS pour la représentation des thésaurus et autres vocabulaires structurés. D'autres vocabulaires RDF, sans être spécifiés par le W3C, sont néanmoins utilisés largement et constituent des standards de fait dans la communauté du Web sémantique, comme FOAF qui est destiné à la représentation des personnes.
Langages de requête
De nombreux langages de requête destinés à interroger les graphes RDF ont été développés. Le langage SPARQL, développé par le W3C, est destiné à devenir le standard en ce domaine.
Voici un exemple de requête SPARQL :
PREFIX foaf: <http://xmlns.com/foaf/0.1/> SELECT ?name ?mbox WHERE { ?x foaf:name ?name. ?x foaf:mbox ?mbox }
Si on applique cette requête au graphe RDF suivant (dans le format Turtle) :
@prefix foaf: <http://xmlns.com/foaf/0.1/> . <http://jlow.me> foaf:name "Johnny Lee Outlaw" . <http://jlow.me> foaf:mbox <mailto:[email protected]> . <http://peter.me> foaf:name "Peter Goodguy" . <http://peter.me> foaf:mbox <mailto:[email protected]> . <http://carol.me> foaf:mbox <mailto:[email protected]> .
On obtient alors le résultat suivant :
| name | mbox |
|---|---|
| "Johnny Lee Outlaw" | <mailto:[email protected]> |
| "Peter Goodguy" | <mailto:[email protected]> |
Pour en savoir plus : cours Wikiversité sur SPARQL
Exemples
Exemple 1 : description RDF d'une personne nommée Eric Miller[1]
L'exemple suivant est tiré du site du W3C[1] qui décrit une ressource avec les déclarations « il y a une personne qui a comme identifiant http://www.w3.org/People/EM/contact#me, dont le nom est Eric Miller, dont l'adresse électronique est [email protected] et qui a le titre de Docteur ».
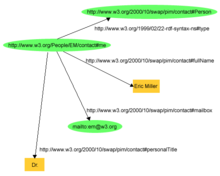
La ressource « http://www.w3.org/People/EM/contact#me » est le sujet.
L'objet est :
- « Eric Miller » (avec le prédicat « quel est son nom ») ;
- [email protected] (avec le prédicat « quel est son adresse électronique ») ;
- « Dr. » (avec le prédicat « quel est son titre »).
Le sujet est un URI.
Les prédicats sont aussi des URI. Par exemple, l'URI pour chaque prédicat est :
- « quel est son nom » est http://www.w3.org/2000/10/swap/pim/contact#fullName,
- « quel est son adresse électronique » est http://www.w3.org/2000/10/swap/pim/contact#mailbox,
- « quel est son titre » est http://www.w3.org/2000/10/swap/pim/contact#personalTitle.
De plus, le sujet a le type (avec le prédicat http://www.w3.org/1999/02/22-rdf-syntax-ns#type) personne (avec l'objet http://www.w3.org/2000/10/swap/pim/contact#Person).
Par conséquent, les triplets RDF suivants peuvent être exprimés :
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/2000/10/swap/pim/contact#fullName, "Eric Miller"
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/2000/10/swap/pim/contact#personalTitle, "Dr."
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/1999/02/22-rdf-syntax-ns#type, http://www.w3.org/2000/10/swap/pim/contact#Person
- http://www.w3.org/People/EM/contact#me, http://www.w3.org/2000/10/swap/pim/contact#mailbox, [email protected]
Exemple 2 : abréviation postale de New York
Certains concepts en RDF sont tirés de la logique et de la linguistique, où les structures sujet-prédicat et sujet-prédicat-objet ont des significations semblables, mais distinctes. Cet exemple démontre :
En français, la déclaration « New York a l'abréviation postale NY » aurait « New York » comme sujet, « a l'abréviation postale » comme prédicat et « NY » comme objet.
Codé comme un triplet RDF, le sujet et le prédicat devraient être nommés par des ressources URI. L'objet pourrait être une ressource ou un élément littéral. Par exemple, dans la Notation3 sous forme de RDF, la déclaration pourrait ressembler à :
<urn:x-states:New%20York> <http://purl.org/dc/terms/alternative> "NY" .
Dans cet exemple, « urn:x-states:New%20York » est l'URI d'une ressource qui représente l'État américain New York, « http://purl.org/dc/terms/alternative » est l'URI du prédicat (dont voici la définition), et "NY" est une chaîne de caractères littérale. Notez que les URI choisis ici ne sont pas standards, et n'ont pas besoin de l'être, tant que leur signification est lisible et accessible.
N-Triples est l'un des formats standard de sérialisation du RDF. Le triplet ci-dessus peut également être représenté de manière équivalente avec le standard RDF/XML comme ci-dessous :
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dcterms="http://purl.org/dc/terms/"> <rdf:Description rdf:about="urn:x-states:New%20York"> <dcterms:alternative>NY</dcterms:alternative> </rdf:Description> </rdf:RDF>
Toutefois, en raison des restrictions sur la syntaxe de QNames (comme dcterms:alternative ci-dessus), il y a certains graphes RDF qui ne sont pas représentables avec RDF/XML.
Exemple 3 : article de Wikipédia sur Tony Benn
D'une manière similaire, étant donné que « http://en.wikipedia.org/wiki/Tony_Benn » identifie une ressource particulière (indépendamment du fait que l'URI est un lien hypertexte, ou encore que la ressource est en réalité l'article Wikipédia sur Tony Benn) pour dire que le titre de cette ressource est "Tony Benn" et que son éditeur est « Wikipédia », on aurait deux assertions qui pourraient être exprimées comme des déclarations RDF valides. Dans le format N-Triples de RDF, ces déclarations pourraient ressembler aux éléments suivants :
<http://en.wikipedia.org/wiki/Tony_Benn> <http://purl.org/dc/elements/1.1/title> "Tony Benn" . <http://en.wikipedia.org/wiki/Tony_Benn> <http://purl.org/dc/elements/1.1/publisher> "Wikipedia" .
Et ces déclarations pourraient être exprimées en RDF/XML comme :
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description rdf:about="http://en.wikipedia.org/wiki/Tony_Benn"> <dc:title>Tony Benn</dc:title> <dc:publisher>Wikipedia</dc:publisher> </rdf:Description> </rdf:RDF>
Pour une personne qui parle français, la même information peut être représentée simplement ainsi :
« Le titre de cette ressource, qui est publiée par Wikipédia, est "Tony Benn". »
Toutefois, RDF intègre les informations d'une manière formelle pour qu'une machine puisse le comprendre. L'objectif de RDF est de fournir un encodage et le mécanisme de l'interprétation afin de représenter les ressources pour les logiciels. Autrement dit, afin que les logiciels puissent accéder et utiliser des informations qui autrement ne pourraient pas être utilisées.
Les deux versions des déclarations ci-dessus sont longues, car une exigence pour une ressource RDF (comme un sujet ou un prédicat), c'est qu'il soit unique. Les ressources soumises doivent être uniques pour permettre d'identifier exactement les ressources décrites. Le prédicat doit être unique afin de réduire les chances de confondre la notion de titre ou d'éditeur par un logiciel. Si le logiciel reconnaît http://purl.org/dc/elements/1.1/title (une définition du concept de titre établie par la Dublin Core Metadata Initiative), il doit aussi savoir que ce titre est différent d'un titre foncier ou un titre honorifique ou tout simplement les lettres t-i-t-r-e mises ensemble.
L'exemple suivant montre comment représenter cette information en combinant plusieurs vocabulaires RDF. Ici, nous ajoutons en plus le thème principal de la page Wikipédia qui est une personne dont le nom est "Tony Benn":
<rdf:RDF xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#" xmlns:foaf="http://xmlns.com/foaf/0.1/" xmlns:dc="http://purl.org/dc/elements/1.1/"> <rdf:Description rdf:about="http://en.wikipedia.org/wiki/Tony_Benn"> <dc:title>Tony Benn</dc:title> <dc:publisher>Wikipedia</dc:publisher> <foaf:primaryTopic> <foaf:Person> <foaf:name>Tony Benn</foaf:name> </foaf:Person> </foaf:primaryTopic> </rdf:Description> </rdf:RDF>
Sérialisation RDF
Le RDF est un modèle de données et non un format. Pour publier un graphe RDF sur le Web, cela nécessite l’utilisation d’une syntaxe dite de sérialisation RDF[2].
Il existe plusieurs formats de sérialisation :
- RDF/XML ;
- Turtle sous-ensemble de Notation3 ;
- N-Triples sous-ensemble de Turtle ;
- JSON-LD ;
- RDFa, recommandé par W3C en 2008.
Exemples d'utilisation

Cet article ou cette section contient trop de liens externes ().
Les liens externes doivent être des sites de référence dans le domaine du sujet. Il est souhaitable — si cela présente un intérêt — de citer ces liens comme source et de les enlever du corps de l'article ou de la section « Liens externes ».
Modèles de données
- SKOS, dont l'objectif est de permettre la publication facile de vocabulaires structurés pour leur utilisation dans le cadre du Web sémantique.
- Dublin Core pour le classement bibliographique.
- RSS version 1.0 est basé sur RDF.
- Mozilla Firefox : le navigateur utilise RDF pour les marque-pages, pour la localisation.
- Wikipédia : en avril 2006, le contenu des espaces de noms 0 et 14 (catégories) des versions anglaises, allemande et française a été rendu disponible sous la forme de 47 millions de triplets.
- XUL : langage d'interface utilisant RDF pour les données.
Portails de données
- Wikidata
- DBpedia: une collection de ressources RDF issues de Wikipédia.
- Le petit laboratoire sémantique : exploiter et interfacer des données sémantiques issues de DBpedia et Data.bnf.fr pour une transposition sous forme de graphe dans le catalogue de la bibliothèque municipale de Fresnes[3],[4].
- data.bnf.fr est le portails d'accès aux données gérées par la BnF répondant aux normes des données ouvertes liées. Le modèle RDF est au cœur de la transition bibliographique opérée par l'ABES et la BnF. Il est utilisé pour structurer les catalogues des bibliothèques via le modèle conceptuel IFLA LRM[5].
- performing-arts.ch est un portail de publication et de gestion des données relatives aux arts de la scène en Suisse mis en place par la Fondation SAPA en 2021. Les données y sont gérées en RDF natif via le logiciel Metaphactory. Un SPARQL EndPoint est disponible[6].
Outils logiciels
- SYRTIS (Système de gestion de bibliothèque). La société Progilone a créé la solution Syrtis qui permet l'exposition d’un catalogue sur le web de données en RDF[7].
- Researchspace est une solution open source qui propose un outil de gestion et de publication en ligne des données RDF dont le développement a été confié à la société allemande Metaphacts et dont ont été tirés par la suite les produits dérivés suivants :
- glam-community [8], solution open source utilisée dans le domaine culturel par SARI et la Fondation SAPA.
- Metaphactory, produit commercial proposé par la société Metaphacts. La solution est surtout utilisée dans le domaine industriel.
- WissKI (de)
- Atomgraph
Notes et références
- ↑ a b et c (en) « RDF Primer », W3C (consulté le ).
- ↑ Myriam Pauillac, « Web des données et archives – quel intérêt ? » [html], sur Anaphore; solution numériques innovantes; archives et patrimoine, (consulté le )
- ↑ Pierre BOURNERIE, « Le petit laboratoire sémantique : expérimentation à la BM de Fresnes », sur transition-bibliographique.fr, (consulté le )
- ↑ Pierre BOURNERIE, « Enrichir son portail et gérer les fichiers d’autorité : l’exemple de la BM de Fresnes », sur transition-bibliographique.fr, (consulté le )
- ↑ « Vers de nouveaux SGB », sur transition-bibliographique.fr, (consulté le )
- ↑ (en) « SPARQL EndPoint », sur performing-arts.ch (consulté le ).
- ↑ Virginie DELAINE et Bénédicte FROCAUT, « Compte-rendu de l’atelier Syrtis de Progilone », sur transition-bibliographique.fr, (consulté le )
- ↑ voir également le suivi des bugs : https://bitbucket.org/metaphacts/metaphacts-community
Articles connexes
Liens externes
- Wikiversité, cours SPARQL : RDF en bref
- (en) Resource Description Framework sur le site du W3C
- RDF Primer=Initiation à RDF, recommandation du traduit par J.J.Solari, . D'autres recommandations autour de RDF traduites en Français sur le site de JJ.Solari.
- Cadre de Description des Ressources : Concepts et Syntaxe Abstraite, recommandation du , traduite en français (2006).
- Spécification (1999), traduite en français.
- Séminaire IRI 2011/2012, extrait de l'intervention de Fabien Gandon sur la notion de RDF.
v · m | |||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Contexte | |||||||||||||||||||
| Semantic Web Stack |
| ||||||||||||||||||
| Autres ontologies | |||||||||||||||||||
| Articles liés | |||||||||||||||||||
v · m Formats d'échange de données | |
|---|---|
| Formats lisibles | |
| Formats binaires | |
 Portail de l’informatique
Portail de l’informatique  Portail du Web sémantique
Portail du Web sémantique








