Konjugált gradiens módszer
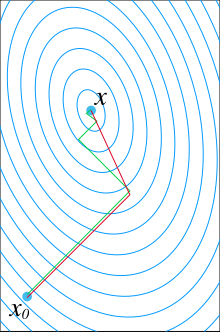
A matematikában a konjugált gradiens módszer bizonyos, szimmetrikus és pozitív definit mátrixszal rendelkező lineáris egyenletrendszerek numerikus megoldására szolgáló algoritmus. A konjugált gradiens módszer egy iterációs módszer, mely alkalmazható olyan rendszerek kezelésére is, melyek túl nagyok ahhoz, hogy direkt módon Cholesky-felbontással megoldhatók legyenek. Ezek főként parciális differenciálegyenletek megoldásakor merülnek fel.
A konjugált gradiens módszer használható olyan optimalizációs problémák megoldására is, mint például az energiaminimalizáció.
A bikonjugált gradiens módszer a fenti módszer általánosítása nemszimmetrikus mátrixokra. A nemlineáris egyenletrendszerek minimumának meghatározására többféle nemlineáris konjugált gradiens módszer létezik.
A módszer leírása
Adott a következő lineáris egyenletrendszer
- Ax = b
ahol A egy valós, szimmetrikus (ha AT = A), pozitív definit, n×n-es mátrix.
Jelöljük az egyenletrendszer egyedüli megoldását x*-gal.
A konjugált gradiens módszer mint direkt módszer
Vegyünk két nem-zéró vektort, u-t és v-t, melyek egymás konjugáltjai, ha

Mivel A szimmetrikus és pozitív definit, a bal oldalt belső szorzatként definiálhatjuk

Két vektor konjugált, ha ortogonálisak, és a belső szorzatukra fennáll a fenti összefüggés. A konjugált tulajdonság szimmetrikus reláció: ha u konjugálja v, akkor v konjugáltja u.
Tegyük fel, hogy {pk} n db kölcsönösen konjugált vektorokból képzett sorozat. Ekkor pk bázist alkot Rn felett, so így ebben a bázisban az x* megoldást kiterjeszthetjük:

A koefficiens a következőképpen adódik:



Ez az eredmény egy valószínűség, mely eleget tesz a fenti belső szorzat kritériumának. Ez a következő módszert szolgáltatja az Ax = b egyenlet megoldására. Először megkeressük az n db konjugált vektor sorozatát, majd kiszámítjuk αk koefficienseket.
A konjugált gradiens módszer mint iterációs módszer
Ha megfelelően választjuk meg pk-t, nincs szükség az összes koefficiens kiszámítására, hogy jó közelítéssel megadjuk x*-t.Tehát ez esetben a konjugált gradiens módszert, mint iterációs módszert alkalmazzuk. Ez lehetővé teszi olyan egyenletrendszerek megoldását, melyeknél n túl nagy, és ezért direkt megoldásuk túl sok időt venne igénybe.
Az x* első közelítését jelöljük x0–lal. Tegyük fel, hogy x0 = 0. Az x0-lal kezdve a megoldást keressük, és minden iterációs lépésben szükségünk van egy olyan mutatóra, mely megadja, mennyire jutottunk közel x*-hoz. A mutató onnan adódik, hogy x* szintén egy négyzetes függvény minimum helye, vagyis ha f(x) egyre kisebb, akkor egyre közelebb jutunk x* értékéhez:

Ez a képlet sugallja, hogy a p1 bázisvektor az f függvény gradiense az x = x0 helyen, és p1 egyenlő Ax0‒b. Ha x0 = 0, akkor p1 = ‒b. A többi bázisvektor a gradiens konjugáltja, ennélfogva ezt a módszert konjugált gradiens módszernek nevezzük.
Legyen rk a k-adik lépés maradéka:

Mivel rk az f függvény negatív gradiense az x = xk helyen, ezért a gradiens módszer abból állna, hogy módosítsa rk irányát. Itt feltesszük, hogy pk irányai egymás konjugáltjai, így azt az irányt választjuk, amely legközelebb esik rk –hoz. Ez a következő kifejezéshez vezet:

A megoldó algoritmus
Néhány egyszerűsítés, a következő algoritmusra vezet Ax = b megoldásában. A kezdő x0 vektor lehet egy megoldáshoz közeli szám, avagy nulla.
- ismétlés
- ha rk+1 elegendően kicsiny akkor fejezze be a ciklust vége ha
- vége ismétlés
- Az eredmény: xk+1









Példa kód a konjugált gradiens módszerre Octave programnyelvben
function [x] = conjgrad(A,b,x0) r = b - A*x0; w = -r; z = A*w; a = (r'*w)/(w'*z); x = x0 + a*w; B = 0; for i = 1:size(A)(1); r = r - a*z; if( norm(r) < 1e-10 ) break; end if B = (r'*z)/(w'*z); w = -r + B*w; z = A*w; a = (r'*w)/(w'*z); x = x + a*w; end end
A konjugált gradiens módszer előfeltétel megadásával
Néhány esetben a gyors konvergencia eléréséhez szükség van előfeltétel megadására. A konjugált gradiens módszer ez esetben a következő formában adható meg:
- ismétlés
- ha rk+1 elegendően kicsiny akkor fejezze be a ciklust vége ha
- vége ismétlés
- Az eredmény xk+1









A fenti formulákban M az előfeltétel, és ez is szimmetrikus és pozitív definit. Ez ekvivalens az előfeltétel nélküli konjugált gradiens módszerrel, abban az esetben, ha érvényesül:
- ,

ahol


Források
- Hestenes, Magnus R., Stiefel, Eduard (1952. December). „Methods of Conjugate Gradients for Solving Linear Systems” (PDF). Journal of Research of the National Bureau of Standards 49 (6). [2010. május 5-i dátummal az eredetiből archiválva]. (Hozzáférés: 2010. április 14.)
- Kendell A. Atkinson (1988), An introduction to numerical analysis (2nd ed.), Section 8.9, John Wiley and Sons. ISBN 0-471-50023-2
- Mordecai Avriel (2003). Nonlinear Programming: Analysis and Methods. Dover Publishing. ISBN 0-486-43227-0.
- Gene H. Golub and Charles F. Van Loan, Matrix computations (3rd ed.), Chapter 10, Johns Hopkins University Press. ISBN 0-8018-5414-8
 Matematikaportál • összefoglaló, színes tartalomajánló lap
Matematikaportál • összefoglaló, színes tartalomajánló lap






