Pengolahan bahasa alami
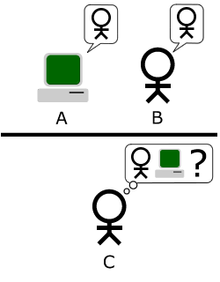
Pengolahan bahasa alami (disingkat PBA; Inggris: natural language processing, disingkat NLP) adalah cabang ilmu komputer, linguistik, dan kecerdasan buatan yang mengkaji interaksi antara komputer dan bahasa (alami) manusia, khususnya cara memprogram komputer untuk mengolah data bahasa alami dalam jumlah besar. Hasilnya adalah komputer mampu "memahami" isi dokumen, termasuk nuansa bahasa di dalamnya. Dengan ini, komputer dapat dengan akurat mengambil informasi dan wawasan dari dokumen sekaligus mengelompokkan dan menata dokumen-dokumen itu sendiri.
Kajian NLP antara lain mencakup segmentasi wicara, segmentasi teks, penandaan kelas kata, dan pengawataksaan makna. Meski kajiannya dapat mencakup teks dan wicara, pengolahan wicara telah berkembang menjadi suatu bidang kajian terpisah.
Sejarah
Pengolahan bahasa alami berawal pada tahun 1950-an. Pada 1950, Alan Turing memublikasikan artikel yang berjudul "Computing Machinery and Intelligence" yang mengusulkan ujian yang sekarang dikenal sebagai uji Turing menjadi salah satu syarat kecerdasan.
Metode
Pada awal perkembangannya, banyak sistem pengolah bahasa didesain dengan metode simbolik, yaitu penyusunan aturan secara manual dengan kamus, misal penyusunan tata bahasa atau aturan heuristik untuk pemotongan kata.[1][2]
Sejak "revolusi statistik"[3][4] pada akhir 1980-an dan pertengahan 1990-an, banyak penelitian pengolahan bahasa alami bergantung pada pemelajaran mesin. Paradigma pemelajaran mesin ini memakai statistika inferensi untuk mempelajari tata bahasa secara otomatis dari sebuah korpus.
Lihat pula
- 1 the Road
- Linguistik komputasi
- Pemahaman kueri
- Pembelajaran bahasa berbantuan komputer
- Pemelajaran dalam
- Penambangan teks biomedis
- Penelaahan berbantuan komputer
- Pengambilan informasi
- Pengolahan istilah majemuk
- Pengolahan linguistik dalam
- Pengolahan wicara
- Penilaian esai otomatis
- Penjawaban pertanyaan
- Penyederhanaan teks
- Perluasan kueri
- Semantik tersebar
- Teknologi bahasa
- Teknologi komunikasi dan bahasa
- Temu balik informasi
- Uji-baca
- Word2vec
Referensi
- ^ Winograd, Terry (1971). Procedures as a Representation for Data in a Computer Program for Understanding Natural Language (Tesis). http://hci.stanford.edu/winograd/shrdlu/.
- ^ Schank, Roger C.; Abelson, Robert P. (1977). Scripts, Plans, Goals, and Understanding: An Inquiry Into Human Knowledge Structures. Hillsdale: Erlbaum. ISBN 0-4709-9033-3.
- ^ Johnson, Mark (2009). "How the statistical revolution changes (computational) linguistics". Proceedings of the EACL 2009 Workshop on the Interaction between Linguistics and Computational Linguistics.
- ^ Resnik, Philip (5 Februari 2011). "Four revolutions". Language Log.
Bacaan lebih lanjut
Wikimedia Commons memiliki media mengenai Pengolahan bahasa alami.
 Portal Bahasa
Portal Bahasa

- Bates, M. (1995). "Models of natural language understanding". Proceedings of the National Academy of Sciences of the United States of America. 92 (22): 9977–9982. doi:10.1073/pnas.92.22.9977. PMC 40721
 . PMID 7479812.
. PMID 7479812. - Steven Bird, Ewan Klein, dan Edward Loper (2009). Natural Language Processing with Python. O'Reilly Media. ISBN 978-0-5965-1649-9. Pemeliharaan CS1: Menggunakan parameter penulis (link)
- Daniel Jurafsky dan James H. Martin (2008). Speech and Language Processing (edisi ke-2). Pearson Prentice Hall. ISBN 978-0-1318-7321-6. Pemeliharaan CS1: Menggunakan parameter penulis (link)
- Kurdi, Mohamed Zakaria (2016). Natural Language Processing and Computational Linguistics: speech, morphology, and syntax. 1. ISTE-Wiley. ISBN 978-1-8482-1848-2.
- Kurdi, Mohamed Zakaria (2017). Natural Language Processing and Computational Linguistics: semantics, discourse, and applications. 2. ISTE-Wiley. ISBN 978-1-8482-1921-2.
- Christopher D. Manning, Prabhakar Raghavan, dan Hinrich Schütze (2008). Introduction to Information Retrieval. Cambridge University Press. ISBN 978-0-5218-6571-5. Pemeliharaan CS1: Menggunakan parameter penulis (link) Tersedia pula versi HTML dan PDF resmi tanpa biaya.
- Christopher D. Manning dan Hinrich Schütze (1999). Foundations of Statistical Natural Language Processing. The MIT Press. ISBN 978-0-2621-3360-9. Pemeliharaan CS1: Menggunakan parameter penulis (link)
- David M. W. Powers dan Christopher C. R. Turk (1989). Machine Learning of Natural Language. Springer-Verlag. ISBN 978-0-3871-9557-5. Pemeliharaan CS1: Menggunakan parameter penulis (link)

| Pengawasan otoritas: Perpustakaan nasional |
|
|---|






