Histograma

Un histograma és una representació gràfica associada a una variable estadística contínua (o discreta amb molts valors diferents) per visualitzar les freqüències de les dades. Es construeix a partir d'una taula de freqüències o distribució de freqüències amb les dades agrupades en classes. Els histogrames més senzills, i que s'utilitzen més, són els que tenen totes les classes de la mateixa amplada,[1] però a les aplicacions pràctiques també apareixen histogrames amb classes de diferent amplada.[2][3] Malgrat la seva gran utilització, l'elecció del nombre de classes i l'amplada de les mateixes sovint és problemàtica. L'histograma és una de les Set Eines de la Qualitat.[4]
Tipus d'histogrames i propietats
Histogrames amb classes (o intervals) d'igual amplada
Com a primer exemple, les següents dades són les notes d'un examen amb 20 estudiants:

La taula de freqüències d'aquestes dades és
![{\displaystyle {\begin{array}{cc}\hline \mathbf {Interval} &\mathbf {Freq{\ddot {u}}{\grave {e}}ncia\ absoluta} \\\hline [0,2]&1\\(2,4]&4\\(4,6]&7\\(6,8]&6\\(8,10]&2\\\hline \mathbf {Total} &\mathbf {20} \\\hline \end{array}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/fb29c54e6d55636573827d2eb3ee81e5ac07fec5)
Aquí s'ha utilitzat la notació habitual dels Intervals, on designa tots els nombres entre 0 i 2, inclosos 0 i 2; designa tots els nombres entre 2 i 4, exclòs el 2 i inclòs el 4, etc. Vegeu a la pàgina Taula de freqüències unes indicacions sobre aquest punt.
![{\displaystyle [0,2]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/120ef5837b0c64a40a2333f5aefd3c36fc458e91)
![{\displaystyle (2,4]}](https://wikimedia.org/api/rest_v1/media/math/render/svg/95f52b9b2ea041f44cbbb81e8bd575b236cfaace)
Un histograma d'aquestes dades consisteix en una representació gràfica on a l'eix d'abscisses hi ha les classes, i a sobre de cada classe es dibuixa un rectangle d'alçada proporcional a la freqüència de la classe. A la Figura 2 hi ha l'histograma corresponent a aquesta taula de freqüències absolutes. En lloc de les freqüències absolutes poden utilitzar-se les freqüències relatives, els percentatges, etc.; l'únic que canvia és l'escala vertical.

Histograma amb classes de diferent amplada
A la pràctica, molt sovint la taula de freqüències té classes de diferents amplades. Per exemple, la següent taula mostra la superfície (en ) dels habitatges de Catalunya l'any 2011[5] que conté classes d'amplades 15, 30 i 120

![{\displaystyle {\begin{array}{lrr}\hline {\mathit {Superf{\acute {\imath }}cie}}\ (m^{2})&{\mathit {Percentatge}}\\\hline ~~~[15,30]&~0,3\\~~~(30,45]&~3,6\\~~~(45,60]&14,4\\~~~(60,75]&22,7\\~~~(75,90]&27,4\\~~(90,105]&11,8\\(105,120]&~7,2\\(120,150]&~6,0\\(150,180]&~2,7\\(180,300]&~3,9\\\hline \mathbf {Total} &\mathbf {100} &\\\hline \end{array}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/3d09585a325a15d1708612df6430879f91d40034)

La representació directa de les classes amb els rectangles proporcionals a la freqüència (vegeu la Figura 3) mostra una imatge distorsionada de les dades, ja que sembla que molts habitatges tinguin entre 180 i 300 , mentre que aquesta classe només conté el 3,9 % dels habitatges. Això és a causa del fet que la impressió visual d'un rectangle depèn de l'àrea i no de l'alçada. El principi general de construcció dels histogrames[3][2] és
En un histograma, les àrees dels rectangles de les classes han de ser proporcionals a les freqüències
Aplicant aquest principi, l'altura d'una classe amb amplada i freqüència absoluta és




on és una constant que determina l'escala vertical. Cal notar que si totes les classes tenen la mateixa amplada, llavors les altures dels rectangles queden proporcional a les freqüències, tal com s'ha fet a la secció anterior.

Si utilitzem freqüències relatives o percentatges (etc.) aleshores

on són les freqüències relatives i són els percentatges. En aquesta secció prendrem , ja que llavors les unitats de l'eix vertical de l'histograma són la freqüència absoluta (o freqüència relativa o percentatge, etc.) per unitat d'àrea.



A l'exemple dels habitatges, les unitats de l'eix vertical són el percentatge d'habitatges per de superfície i les altures dels rectangles són les següents:
![{\displaystyle {\begin{array}{lrr}\hline {\mathit {Superf{\acute {\imath }}cie}}\ (m^{2})&{\mathit {Percentatge}}&{\mathit {Altura}}\\\hline ~~~[15,30]&~0,3&0,02\\~~~(30,45]&~3,6&0,24\\~~~(45,60]&14,4&0,96\\~~~(60,75]&22,7&1,51\\~~~(75,90]&27,4&1,85\\~~(90,105]&11,8&0,76\\(105,120]&~7,2&0,48\\(120,150]&~6,0&0,20\\(150,180]&~2,7&0,09\\(180,300]&~3,9&0,03\\\hline \mathbf {Total} &\mathbf {100} &\\\hline \end{array}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/b339e0501d4edef4e7a8aa214f5a289bf187c601)
A la Figura 4 hi ha l'histograma corresponent.

La fórmula (*) es dedueix de la següent manera: considerem una taula de freqüències (s'utilitza freqüències absolutes, però el raonament és anàleg amb freqüències relatives, percentatges, etc.), i designem per les àrees dels rectangles corresponents a les classes respectivament:



Per tal que la impressió visual sigui correcta volem que si, per exemple, la freqüència d'una classe és el doble que la d'una altra, l'àrea corresponent a la primera classe ha de ser el doble que la de la segona, això és,

Llavors,

Com que això valdrà per totes les classes, s'obté

D'on


Elecció del nombre de classes
A la pràctica, sovint no és fàcil decidir el nombre de classes, ja que si s'utilitzen poques classes, s'amaguen les característiques de la variable, i, si se n'utilitzen moltes, llavors queden classes amb pocs elements. Tal com comenta Wilkinson"[6] [l'histograma] és un dels gràfics més difícils de construir. Apareixen diversos problemes, entre ells, escollir el nombre de classes i decidir on posar els punts de tall".
La regla més antiga per calcular el nombre de classes, i una de les que encara s'utilitza més, és la regla de Sturges[7] de 1926 (els paquets estadístics la utilitzen a menys que es digui una altra cosa): per a observacions, el nombre de classes recomanat és




L'argument de Sturges és que si es té, per exemple (utilitzant els seus nombres) 16 objectes, atès que , la manera més normal de repartir-los en grups és fent 5 grups de mides 1, 4, 6, 4, 1 (vegeu la Figura 5), que són els coeficients binomials . Més generalment, si tenim objectes, llavors, atès que






Però diversos autors han argumentat que aquest nombre de classes pressuposa una distribució simètrica de les dades i, de forma subjacent, normalitat, i que si hi ha asimetria (vegeu més avall la secció sobre distribucions simètriques i asimètriques) cal prendre un nombre més gran d'intervals.[8]
Una altra regla és la de Terrell and Scott:[9]
![{\displaystyle k\geq {\sqrt[{3}]{2N}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/bfcd6d6026d71bcc2da18401deb3b7bfed4b4e01)
que justifiquen sobre la base de propietats asimptòtiques.
També és important la regla de Scott:[10]
![{\displaystyle k\approx {\frac {3,49\ S}{\sqrt[{3}]{N}}},}](https://wikimedia.org/api/rest_v1/media/math/render/svg/adc1f71c1e56b78b3b35a86d13cb0e13fc11eb4a)
on és una estimació de la desviació típica de la població, per exemple, la desviació típica modificada de les dades. Aquesta regla està calculada a partir d'una distribució normal, però Scott[10] argumenta que també serveix per a distribucions més generals.

Amplada de les classes
El nombre de classes que s'ha calculat a l'apartat anterior es refereix inicialment a classes d'igual amplada. Per calcular aquesta amplada s'utilitza el rang de la distribució, que és la diferència entre l'observació més gran i la més petita, i que designarem per :




Finalment, en molts casos, cal ajuntar diverses classes consecutives a l'esquerra i a la dreta per evitar que hi hagi classes buides o amb molt poques dades.
Histograma normalitzat o de densitat
Es diu que un histograma està normalitzat quan l'àrea total és 1; també es diu que és un histograma de densitat perquè és l'equivalent de la funció de densitat d'una variable aleatòria. Si s'utilitza les freqüències absolutes, aleshores les altures dels rectangles són:



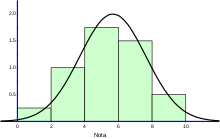
L'histograma normalitzat permet comparar-lo amb la funció de densitat d'una variable aleatòria. A la Figura 6 hi ha representat l'histograma normalitzat de les notes de la primera secció, juntament amb la densitat d'una variable aleatòria normal amb mitjana i variància iguals a les de les notes.
Característiques de forma d'una distribució
Distribucions unimodals i multimodals
Cal recordar que la moda d'una distribució de freqüències és el valor de la variable que es repeteix més sovint, és a dir, la que té la freqüència més gran. Quan la variable és contínua (o discreta amb molts valors diferents) aleshores es parla de classe modal o interval modal com aquella classe que té la freqüència més gran. Les distribucions amb l'histograma com els de les Figures 2 i 4 que tenen forma de muntanya, ja que només tenen un màxim, o equivalentment, una sola moda, es diu que són unimodals. Les distribucions corresponents a histogrames com el de la Figura 1 que tenen forma de serralada, pel fet que tenen dos o més màxims locals, és a dir, tenen dues o més modes, es diu que són bimodals, trimodals, etc. En particular, la distribució de la Figura 1 és bimodal.
Distribucions simètriques i asimètriques (skewness)
En aquesta secció i la següent comentarem dues característiques més de la forma d'una distribució. Ens referirem només a distribucions unimodals.
L'histograma de la Figura 2 és aproximadament simètric, mentre que el de la Figura 4 és asimètric. Per mesurar el grau d'asimetria d'una distribució, Fisher va introduir el coeficient d'asimetria (en anglès, skewness):






Quan la distribució és perfectament simètrica, llavors .

Quan es diu que la distribució és asimètrica a la dreta, o esbiaixada a la dreta, com en el cas de les dades de l'histograma de la Figura 4, que . Quan es diu que la distribució és asimètrica a l'esquerra, o esbiaixada a l'esquerra, com a la Figura 7.



La distribució de les notes de l'histograma de la Figura 2 tenen un coeficient d'asimetria , que vol dir que és lleugerament asimètric a l'esquerra.

Curtosi o apuntament


Tal com s'ha fet a la Figura 6, es pot comparar un histograma normalitzat amb una densitat normal amb la mateixa mitjana i variància que la variable estadística que s'estudiï. Si l'histograma normalitzat és més punxegut que la densitat normal (vegeu la Figura 8) es diu que la distribució de freqüències és leptocúrtica, en cas contrari (Figura 9) es diu que és platicúrtica, i si és aproximadament igual es diu que és mesocúrtica.
Per quantificar el grau de semblança amb l'apuntament de la distribució normal, Fisher va introduir el coeficient de curtosi o apuntament:





![{\displaystyle {\frac {E[(X-m)^{4}]}{{\big (}E[(X-m)^{2}]{\big )}^{2}}}=3.}](https://wikimedia.org/api/rest_v1/media/math/render/svg/298ee85b80b52522c224e4b408fec6fd6fd7a5d4)





D'altra banda, per a qualsevol variable aleatòria (no constant, amb moment de 4t ordre finit) tenim [11] que , d'on , i per tant,



Histograma de freqüències acumulades
En un histograma de freqüències acumulades (absolutes o relatives, percentatges, etc.) es representen les freqüències acumulades; també s'anomena ogiva,[12] però aquest terme també s'utilitza per al polígon de freqüències acumulades (vegeu la següent secció). La següent taula mostra les freqüències relatives acumulades de l'exemple de les 20 notes que hem comentat anteriorment:
![{\displaystyle {\begin{array}{ccc}\hline \mathbf {Interval} &\mathbf {Freq{\ddot {u}}{\grave {e}}ncia\ relativa} &\mathbf {Freq{\ddot {u}}{\grave {e}}ncia\ relativa\ acumulada} \\\hline [0,2]&0,05&0,05\\(2,4]&0,2~&0,25\\(4,6]&0,35&0,6~\\(6,8]&0,3~&0,9~\\(8,10]&0,1&1\\\hline \mathbf {Total} &\mathbf {1} &\\\hline \end{array}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/531fb6344aa5bfb8a66b7660a289cd712d952d55)

L'histograma de freqüències relatives acumulades es mostra a la Figura 10.
Polígons de freqüències i ogives
Polígon de freqüències
El polígon de freqüències (relatives, absolutes, percentatges, etc.) d'una distribució de freqüències es construeix a partir de l'histograma corresponent ajuntant amb una línia poligonal simple els punts mitjans de les classes (que s'anomenen marques de classe).

Actualment, el seu principal interès és en l'estimació de densitats,[13] i per aquest motiu ens restringirem a la utilització que allí se'n fa; així, només considerarem els polígons de freqüències relatives normalitzats, amb classes de la mateixa mida i on s'han ampliat el nombre de classes amb dues (de freqüència zero), a l'esquerra i dreta respectivament de les classes originals, i de la mateixa amplada que les altres (vegeu la Figura 11).
El polígon de freqüències així construït té una àrea total entre la línia poligonal i l'eix d'abscisses igual a 1[14] i, llavors, tal com diu Scott, és una funció de densitat legítima (bona fide), ja que és una funció no negativa amb integral igual a 1.
Polígon de freqüències acumulades o ogiva

S'anomena polígon de freqüències acumulades o, tal com s'ha comentat a la secció anterior, ogiva,[15] a una línia poligonal com la descrita a la Figura 12. La construcció gràfica a partir de l'histograma de freqüències acumulades és directe. Més concretament, a partir de la taula de freqüències relatives acumulades,
![{\displaystyle {\begin{array}{cccc}\hline \mathbf {Classe} &\mathbf {Freq{\ddot {u}}{\grave {e}}ncia\ relativa} &\mathbf {Freq.rel.acumulada} \\\hline [c_{1},c_{2}]&f_{1}&fa_{1}\\(c_{2},c_{3}]&f_{2}&fa_{2}\\\vdots &\vdots &\vdots \\(c_{k},c_{k+1}]&f_{k}&1\\\hline \mathbf {Total} &\mathbf {1} &\\\hline \end{array}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/2edb205a683bee63ec1197579f97656b781f9716)
on és la freqüència relativa acumulada de la classe









i, per tant, és l'equivalent a la funció de distribució d'una variable aleatòria.
Referències
- ↑ Moore, David S.. Estadística aplicada básica. Barcelona: Antonio Bosch, 1995. ISBN 84-85855-80-9.
- ↑ 2,0 2,1 Calot, G.. Curso de Estadística Descriptiva. Madrid: Paraninfo, 1970, p. 46.
- ↑ 3,0 3,1 Freedman, D., Pisani, R., Purves, R.Adhikari, A.. Estadística. 2. ed. Barcelona: Antonio Bosch editor, 1993, p. 36. ISBN 84-85855-68-X.
- ↑ Métodos estadísticos. Control y mejora de la calidad. Volum I, pàg. 25. Albert Prat Bartés, Xavier Tort-Martorell Llobés, Pere Grima Cintas, Lourdes Pozueta Fernández. Edicions Universitat Politècnica de Catalunya, 1997. ISBN 84-8301-222-7
- ↑ Està basada en la taula de l'idescat https://www.idescat.cat/pub/?id=censph&n=311 consultada el 5/05/20. Per poder dibuixar l'histograma hem suposat que tots els habitatges tenen una superfície entre 15 i 300 .
- ↑ Wilkinson, Leland.. The grammar of graphics. 2a edició. Nova York: Springer, 2005. ISBN 0-387-24544-8.
- ↑ Sturges, Herbert A. «The Choice of a Class Interval». Journal of the American Statistical Association, 21, 153, 01-03-1926, pàg. 65–66. DOI: 10.1080/01621459.1926.10502161. ISSN: 0162-1459.
- ↑ Doane, D. P. «Aesthetic frequency classifications». The American Statistician, Vol. 30, num. 4, 1976, pàg. 181-183.
- ↑ Terrell, George R.; Scott, David W. «Oversmoothed nonparametric density estimates.». J. Amer. Statist. Assoc. 80 (1985), no. 389, 209–214.
- ↑ 10,0 10,1 Scott, David W. «On optimal and data-based histograms» (en anglès). Biometrika, 66, 3, 01-12-1979, pàg. 605–610. DOI: 10.1093/biomet/66.3.605. ISSN: 0006-3444.
- ↑ Loeve, Michel.. Teoría de la probabilidad. Madrid: Tecnos, D.L. 1976, p. 157. ISBN 84-309-0663-0.
- ↑ Everitt, Brian.. The Cambridge dictionary of statistics. 3a edició. Cambridge, UK: Cambridge University Press, 2006. ISBN 978-0-511-24688-3.
- ↑ Scott, David W.. Multivariate Density Estimation : Theory, Practice, and Visualization.. 2a edició. Hoboken: Wiley, 2015. ISBN 978-1-118-57548-2.
- ↑ Scott, David W.. Multivariate Density Estimation : Theory, Practice, and Visualization.. 2a edició. Hoboken: Wiley, 2015, p.101. ISBN 978-1-118-57548-2.
- ↑ Spiegel, Murray R.. Teoría y problemas de estadística. 1. ed. en español. México: McGraw-Hill, 1970, p. 30. ISBN 968-451-066-7.
Enllaços externs
- A Method for Selecting the Bin Size of a Histogram
| Distribució de probabilitat contínua |
| ||||||
|---|---|---|---|---|---|---|---|
| Distribució de probabilitat discreta | Índex de dispersió | ||||||
| Correlació | Coeficient de correlació de Pearson · Correlacions per rang (Spearman, Kendall) · Correlació creuada · Correlació parcial · Covariància | ||||||
| Taules de resum | |||||||
| Gràfics estadístics | Diagrama de barres · Diagrama de caixes · Diagrama de control · Correlograma · Diagrama de dispersió · Histograma · Diagrama de punts i línies · Diagrama d'àrees · Diagrama Q-Q · Diagrama de tiges i fulles · Diagrama de sectors · Diagrama de xarxa | ||||||

